Manual¶
The Snap Machine Learning (Snap ML) Library is designed to offer fast training of generalized linear models and tree based models. The library is under development and currently supports the following machine learning models:
Linear Regression¶
LinearRegression fits a linear model with coefficients 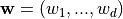 to minimize the residual sum
of squares between the predicted responses
to minimize the residual sum
of squares between the predicted responses 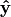 and the true labels
and the true labels 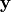 of the training data.
of the training data.
In order to prevent the model from overfitting you have the option to impose an
 or an
or an 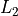 norm penalty on the size of the coefficients.
norm penalty on the size of the coefficients.
Ridge Regression adds an
-regularization term to the least-squares loss.
Mathematically it solves the following optimization problem: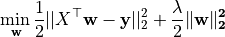
Lasso adds an
-regularization term to the least-squares loss.
Mathematically it solves the following optimization problem: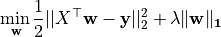
In both cases ![X=[{\bf x}_1,...,{\bf x}_n]](_images/math/2e2f8e3140e270db5d03a8519a19f8455bd665c0.png) denotes the training data matrix with samples
denotes the training data matrix with samples ![\{{\bf x}_i\}_{i\in [n]}](_images/math/8ac96ca9da02ddf3f547e5dc1e1cdadef1bd8618.png) in its columns and
in its columns and 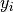 are the corresponding labels.
The regularization strength is controlled by the regularization parameter
are the corresponding labels.
The regularization strength is controlled by the regularization parameter 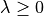 ; the larger
; the larger 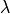 the more robust the model becomes to overfitting.
the more robust the model becomes to overfitting.
Note
(Regularization Parameter) In order to find an appropriate regularization parameter we recommend to perform cross validation.
Note
(Feature Selection)
As Lasso regression yields sparse models it can be used to perform feature selection. The sparsity can be controlled by - a larger regularization parameter encourages more sparsity.
Snap ML implements different variants of stochastic coordinate descent [SCD] and stochastic dual coordinate ascent [SDCA] as an algorithm to fit the model parameters 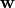 .
In order to optimally support GPUs for training Snap ML implements a parallel asynchronous version of these solvers especially designed to leverage the massive parallelism of modern GPUs [TPASCD].
.
In order to optimally support GPUs for training Snap ML implements a parallel asynchronous version of these solvers especially designed to leverage the massive parallelism of modern GPUs [TPASCD].
To train the LinearRegression model the fit method is used; it takes the training data and the labels 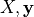 as input and stores the learnt coefficients of the model in its
as input and stores the learnt coefficients of the model in its coef_ member function.
The regularization type can be specified during initialization using the penalty argument.
The trained model can then be used to make predictions by calling the predict method on unlabelled data.
>>> from pai4sk import LinearRegression
>>> import numpy as np
>>> reg = LinearRegression(max_iter = 100, regularizer = 0.1, penalty = 'l2')
>>> X_train = np.array([[0, 0], [1, 1], [2, 2]])
>>> y_train = np.array([0, 1, 2])
>>> reg.fit (X_train, y_train)
>>> reg.coef_
[ 0.495, 0.495]
>>> X_test = np.array([[3, 3], [0, 1]])
>>> reg.predict(X_test)
[2.97, 0.495]
For more details about the API we refer to the snap-ml API.
Support Vector Machine¶
Support Vector Machine (SVM) is a supervised learning method which can be applied for regression as well as classification.
Currently Snap ML implements SupportVectorMachine (SVMs) with a linear kernel function and offers
regularization to prevent the model from overfitting.
Mathematically it solves the following optimization problem:
![\underset{{\bf w}}{\min\,} \sum_i [{\bf x}_i^\top {\bf w} - y_i]_+ +\frac \lambda 2 \|{\bf w}\|_2^2](_images/math/0eddea35f4c53c5f10f013bc00f7f2a9c3baf780.png)
where ![[u]_+=\max(u,0)](_images/math/07a7ad7bf78ce80c574857ce9a949a157eac470c.png) denotes the hinge loss with
denotes the hinge loss with ![\{x_i\}_{i\in [n]}](_images/math/7f5ec56efd11f6bb4c5619c7576bc3cb7e8635c2.png) being the training samples and
being the training samples and 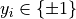 the corresponding labels. The regularization strength
the corresponding labels. The regularization strength 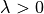 can be controlled by the user through the
can be controlled by the user through the regularizer parameter.
The larger the more robust the model becomes to overfitting.
Snap ML implements stochastic dual coordinate [SDCA] and the GPU optimized [TPASCD] as an algorithm to train the SVM classifier. SDCA runs on the equivalent SVM dual problem formulation:
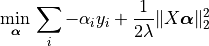
with the constraint ![\alpha_i y_i\in[0,1]](_images/math/aaa5eeca78a2f0cc50f1abb79b78effab16d13d7.png) .
.
To train the model the fit method is used; it takes the training data and the labels 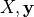 as input and stores the learnt coefficients of the model
as input and stores the learnt coefficients of the model 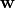 in its
in its coef_ member function. The trained model can then be used to make predictions by calling the predict method on unlabelled data.
>>> from pai4sk import SupportVectorMachine
>>> import numpy as np
>>> reg = SupportVectorMachine(max_iter = 100, regularizer = 1.0)
>>> X_train = np.array([[0, 0], [1, 1], [2, 2]])
>>> y_train = np.array([-1,-1,1])
>>> reg.fit (X_train, y_train)
>>> reg.coef_
[ 0.25, 0.25]
>>> X_test = np.array([[3, 3], [0, 1]])
>>> reg.predict(X_test)
[1,-1]
A full example of training a SupportVectorMachine model in a real application can be found in the PowerAI distribution under /opt/DL/snap-ml-local/examples. For more details about the API we refer to the snap-ml API.
Logistic Regression¶
LogisticRegression is a linear model for classification. A logistic model is used to estimate the probability of an outcome based on the features of the input data. In order to prevent the model from overfitting or regularization can be used.
Mathematically -regularized Logistic Regression solves the following optimization problem composing of the logistic loss and an regularization term:
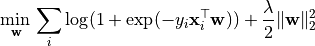
Similarly, -regularized Logistic Regression solves the following optimization problem:
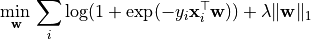
where is the training data matrix with samples in its columns and denote the corresponding labels.
The regularization strength is controlled by the regularization parameter ; the larger the more robust the model becomes to overfitting. can be specified by the user through the regularizer input parameter.
Snap ML implements stochastic coordinate descent [SCD] and stochastic dual coordinate ascent [SDCA] as an algorithm to fit the model parameters . In order to support GPU acceleration Snap ML implements a parallel asynchronous version of these solvers especially designed to leverage the massive parallelism of moderne GPUs [TPASCD].
The model can be trained using the fit method which takes the training data and the labels as input and stores the coefficients of the learnt model in its coef_ attribute. This model can then be used to make predictions by calling the predict method on unlabelled data. The regularization type can be specified at initialization using the penalty argument.
>>> from pai4sk import LogisticRegression
>>> import numpy as np
>>> lr = LogisticRegression(max_iter = 100, regularizer = 0.01, penalty = 'l2')
>>> X_train = np.array([[0, 0], [1, 1], [2, 2]])
>>> y_train = np.array([-1,-1,1])
>>> lr.fit (X_train, y_train)
>>> lr.coef_
[0.145, 0.145]
>>> X_test = np.array([[3,3],[-2,1]])
>>> lr.predict(X_test)
[1,-1]
>>> lr.predict_proba(X_test)
[[0.295, 0.705]
[0.536, 0.464]]
A full example of training a LogisticRegression model in Snap ML can be found in the PowerAI distribution under /opt/DL/snap-ml-local/examples. For more details about the API we refer to the snap-ml API.
Decision Tree¶
Snap ML offers a DecisionTreeClassifier for training a binary decision tree. The training routine is single-threaded and executed on the CPU. Check the snap-ml API for details about the available options or check out the Tutorials for an application example.
Random Forest¶
With the RandomForestClassifier you can train an ensemble of trees. This is usually preferred over a single decision tree as it improves the generalization performance of the model. Snap ML implements a multi-threaded training routine that is executed on the CPU. Check the snap-ml API for details about the available options or check out the Tutorials for an application example.
References¶
| [SCD]: | Y. Nesterov. Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM Journal on Optimization, 2012. |
|---|---|
| [SDCA]: | Shai Shalev-Shwartz and Tong Zhang. Stochastic Dual Coordinate Ascent Methods for Regularized Loss Minimization. Journal of Machine Learning Research, 2013. |
| [TPASCD]: | Thomas Parnell, Celestine Dünner, Kubilay Atasu, Manolis Sifalakis and Haris Pozidis. Tera-Scale Coordinate Descent on GPUs. Journal on Future Generation Computer Systems, 2018. |